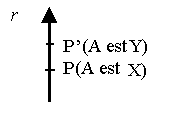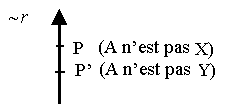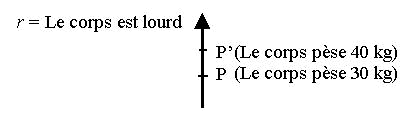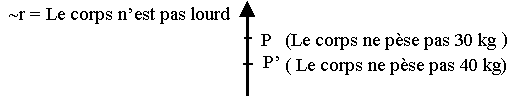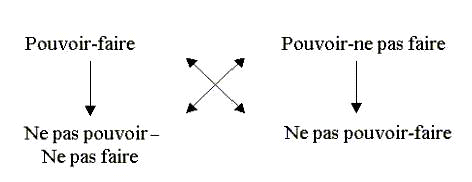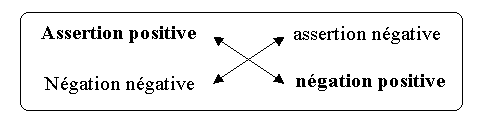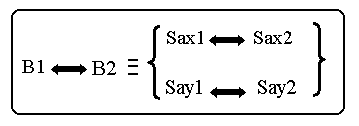![]()
![]()
![]()
![]()


|
|
|
ici un ouvrage en traductologie Chapitre1 repérage linguistique coordonnées d'un élément linguistique remarques importantes chapitre2 définition préliminaire traduction encodage-décodage définition sémiotique de traduction classifications en traduction chapitre3 équations en traduction : équation syntagmatique équation paradigmatique équation sémantique équation temporelle . La société et choix des mots chapitre4 Le terme métatraduction : un néologisme née au Maroc en 2003 chapitre7 Exercices en traduction : une vingtaine de modèles parfaitement ajustés à notre théorie Introduction à la partie pratique des fondements théoriques مــــقدمـــة الجزء التطبيقي من الأسس النظرية للترجمة العلمية Unités syntagmatiques simples وحدات تركيبية بسيطة Unités syntagmatiques complexesوحدات تركيبية مركبة Textes scientifiques vulgariséesنصوص علمية معممة Textes généraux:traductions sans commentaires : ترجمة دون تعلـــــيق نصـــــــــــــوص عــــامـــة
|
Phases de traduction I-
Détermination de la coordonnée sémantique : a.
Point de vue traditionnel b.
Point de vue linguistique contemporain : nouvelle approche de calcul
de coordonnée sémantique c.
Ducrot et Anscombre : analogie entre le contenu comme hypothèse
interne et l’acte illocutionnaire comme hypothèse externe d.
Structures illocutoires et
structures modales e.
Structures modales énonciatives : projection sur les carré sémiotique f.
Modalisation énonciative d’une structure modale II-
Etablissement de l’équation paradigmatique : a.
Repérage des sémiotiques b.
Equations lexicales c.
Equation paradigmatique III-
Phase de Réexpression (modèle graduel et modèle
linéaire de traduction) IV-
Traduction par repérage et grammaire générative : a.
Grammaire générative b.
Mise en évidence
Chapitre
5 :
Introduction :
Dans
ce chapitre sera mise en évidence une nouvelle méthodologie en traduction
scientifique, pédagogiquement
applicable au niveau des classes scientifiques et techniques , mais soupçonnée
d’être appliquée dans tout les domaines de traduction. Si on met le point
sur l’aspect d’applicabilité au niveau des classes scientifiques et
techniques en secondaire qualificatif marocain,
c’est parce que la traduction à ce niveau est en état désastreux :
la traduction au niveau des lycées marocains est réputée matière superflu
,ou disant une espèce en état d’extinction !!…pas de programmes…pas
de normes…pas de système de compétence de traduction…Ce sont des
situations problématiques auxquelles on va essayer de proposer des remèdes dans les chapitres à venir .
Notre projet de traduction est un texte scientifique exprimé dans une
langue de départ , on entreprend traduire ce texte en le réexprimant dans une
langue d’arrivée. L’opération traduisante se fait en trois phases
fondamentales :
I-
Calcul
de la coordonnée sémantique du texte-source C’est
une phase qui décide de la qualité du produit de traduction . Elle doit être
exécuter avec le plus grand soin. Elle est communément nommée phase de compréhension
ou d’analyse ou de traitement .
Diverses
approches d’analyse textuelle ont été mises en œuvre le long de
l’histoire linguistique humaine . Aucune d’entre elles ne se veut définitive
, car en linguistique, les phénomènes évolutifs et dynamiques établissent
toujours leur suprématie . Naturellement, l’approche d’analyse textuelle
que j’ai l’intention de proposer ici , elle aussi, n’a rien de sur commun.
Elle n’est pas définitive et n’englobe pas tout les aspects textuels, mais
seulement les plus pertinents. Cela , on le sait, est un principe général
qu’aucune théorie en analyse textuelle ne peut transgresser .
Mais ce serait une approche qui constitue l’un des accessoires
fondamentaux de notre théorie en traduction. En effet, pas de théorie en
traduction sans théorie en compréhension.
L’objectif général entrepris
dans le cadre de cette approche est la détermination de la coordonnée sémantique
du texte d’origine. Ce qui implique un repérage d’au moins trois
composantes : le sens syntagmatique, le sens lexical et la sens contextuel.
Avant d’entamer l’approche proprement dite, il faut que
soit effectué un ensemble de tâches , bien que classiques et traditionnelles,
sont nécessaires pour quiconque ayant l’intention de comprendre un texte afin
de le traduire . 1)
Activités
préliminaires : La
compréhension textuelle nécessite que soient effectuées des tâches préliminaires
et préparatoires importantes : ·
Détermination
de l’aspect extérieur du texte : le traducteur commence par
observer avec finesse le texte projet de traduction. Il observe notamment
si le texte possède un titre , s’il a une référence, le nombre de
paragraphes, les variations typographiques… ·
Lecture du
texte : mais ce n’est pas n’importe comment , le texte doit être lu
avec un certain degré de concentration et en l’examinant minutieusement .
C’est une lecture consciente qui nécessite , qu’elle soit silencieuse ou à
haute voix, une audition consciente, car le lecteur est en même temps récepteur
et énonciateur . Toutefois, il peut être récepteur mais passif , c’est-à-dire
, il effectue la lecture sans comprendre . Cette audition est à plusieurs degrés
que Ducrot appelle degrés de destinatarité. Ainsi, lorsque l’enseignant
s’adresse à ses apprenants en classe , ces derniers ne reçoivent pas ses
propos de la même manière, si bien qu’il faut varier les niveaux discursifs
à tout instant. Dans le verset 10 de Sorate Alhākka « Nous
l’avons assignée pour vous comme évocation prise en compte par une oreille
consciente » "لنجعلها لكم تذكرة و تعيها
أذن واعية "
. Ce qui veut dire qu’il existe des oreilles inconscientes . Donc, l’échec
communicationnel existe et là une autre reproche pour le schéma de R.Jackobson
en communication linguistique. En outre , la lecture et l’écriture doivent
s’effectuer selon des stratégies explicites qu’on aurait l’occasion de
voir en détails au niveau de la deuxième partie de cette recherche (cf.
Chap4 : Stratégies en traduction ) ·
Détermination du thème général du texte ou l’idée générale,
son genre et son domaine cognitif. ·
Repérage des mots difficiles et dégagement de leurs sèmes
par usages des dictionnaires traditionnels
et des dictionnaires électroniques informatisés.
·
Détermination des unités sémantiques généralement des
paragraphes, et dégagement de l’idée essentielle de chaque unité. ·
Repérage des sémiotiques supposées pertinentes comme la
sémiotique des liens logiques , des anaphores, des déictiques, des mots clés
, des verbes… Remarque :
Le calcul de la coordonnée sémantique est une opération relative . En
effet, cette coordonnée est caractérisée par des degrés très variés dont
le degré minimum est la détermination superficielle du sens du texte, et le
degré maximum est fonction de la capacité de l’interprétateur à
s’infiltrer aux tréfonds du texte par ses compétences linguistiques ,
encyclopédiques et culturelles . On peut même aller plus loin jusqu’à dire
qu’il est impossible d’épuiser les contenus sémantiques d’un texte.
Mais quel degré de compréhension requis pour traduire un texte ? La durée
officielle affectée à la
traduction d’un texte par un professionnel est très limitée. On l’estime
à 600 mots par heure . Par voie de
conséquence , le degré de compréhension est , lui aussi, limité. Le degré
de traitement du texte comme conçu par le Ministère de l’éducation
nationale et de la jeunesse est plus évolué que le degré de compréhension
textuelle dans le but de traduction ; mais il est moins évolué que la
degré d’analyse textuelle. Mais plus le degré de pénétration est profond
plus la traduction sera de bonne augure et bien maîtrisée. Pour mieux
assimiler le sens de ces degrés du contenu sémantique, que l’on considère
l’énoncé suivant : « Le
tonneau est encore à moitié vide » Ducrot et
Anscombre attribuent à cet énoncé
au moins trois contenus sémantiques (cf.:
O. Ducrot et J. C.Anscombre, 1988 : 41): 1)
le posé : C1= [En t0(moment d’instance d’énonciation),le
tonneau est à moitié vide] ; 2)
le présupposé : C2=[En tx>t0, le tonneau ne sera plus à moitié
vide] ; 3)
le contenu déduit : C3=[On est en opération de remplissage du
tonneau] Ce dernier
contenu est déduit par usage de la loi d’abaissement appliquée à C2 ;
C’est-à-dire, si, à tx , le tonneau n’est pas à moitié vide (C2) , alors
il est moins que moitié vide, donc il pourrait être par exemple à trois-quart
vide ; Par conséquent, le niveau du liquide est en train d’augmenter
dans le tonneau, ce qui prouve que nous sommes en train de remplir le tonneau. Maintenant si on
compare les trois contenus dégagés , on s’aperçoit facilement que le
contenu le plus profond sémantiquement
est bien entendu C3. L’énoncé
analysé par Ducrot et Anscombre renferme une unité lexicale décisive :
« encore » . L’équivalent arabe de cette unité « māzāla »
, entité verbale restructurante , ne fonctionne pas comme fonctionne l’entité
« encore » en français( cf. N. HALI .2003 :70-71). Un autre énoncé est proposé par Ducrot (cf. O.Ducrot
.1980 :43) : « Le tonneau est encore seulement à moitié vide »
Pour conclure qu’il s’agit ici d’un processus de
vidage , Ducrot a utilisé, outre la loi d’abaissement , une autre loi
applicable en théorie d’échelles argumentatives , mais seulement pour la négation
descriptive et ne convient pas à la négation métalinguistique,
c’est la loi d’inversion . Ces trois concepts seront illustrés à
travers les exemples suivants qui , en outre, explique l’usage
argumentatif de l’opérateur « même » : 1-
Le corps pèse 30 kg, et même 40 kg. 2-
Cette solution saline est concentrée, et même saturée 3-
La tension aux bornes de ce générateur
est égale 12 v, elle est même égale 14 v 4-
Votre installation électrique
est traversée par un courant intense, et même très intense 5-
Cette solution n’est pas saturée, ni même concentrée. 6-
La tension aux bornes de ce générateur n’est pas égale 14 v, ni même
12 v. 7-
Votre installation n’est pas traversée par un courant très intense,
(ni même intense).
8-
Cet homme n’est pas intelligent, il est un génie Avant
d’entamer l’analyse des énoncés ci-dessus, on doit régler quelques petits
problèmes d’ordre théorique. Considérons
tout d’abord la structure : A est X, et même Y Selon
Ducrot, un locuteur d’une occurrence de cette structure à l’intention de
pousser son allocutaire à tirer une certaine conclusion notée r ,
et ce qui vient avant l’opérateur « même »(X) est un argument en
faveur de cette conclusion , mais ce qui vient après l’opérateur est un
autre argument plus fort que le premier argument.
Dans ce schéma :la flèche représente l’échelle argumentative,
P’ l’argument les plus fort en faveur de r et P l’argument le moins fort
vis-à-vis de P’ .
Voyons maintenant la négation de la structure précédente :
A n’est pas Y, ni même X On remarquera
tout de suite que la négation a nécessité une inversion des arguments :
l’argument fort est devenu faible
en faveur de ~r :
C’est ce qu’on appelle la loi d’inversion.
Traitons à présent les exemples un par un : 1-
Le corps pèse 30 kg,
et même 40 kg
Quant
à la loi d’inversion , on l’utilise lorsqu’on procède à la négation de
la phrase ci-dessus : «
Le corps ne pèse pas 40 kg, ni même 30 kg » et
on obtient l’échelle argumentative suivante :
N.B :
Les conclusions proposées sont à titre indicatif seulement , c’est-à-dire,
ce ne sont pas les seules qu’on puisse dégagées. Pour
les exemples de 2 à 7 ,nous nous contenterons de tirer des exemples de
conclusions et nous repérons les arguments :
Observons enfin la phrase 8 : Cet
homme n’est pas intelligent, il est un génie. On
sait que les deux unités « intelligent » et « génie »
forme une échelle argumentative, car on peut dire : « Cet homme est
intelligent, et même un génie ».
Mais , la phrase en question ne peut pas être soumise à la loi d’inversion.
La raison c’est qu’il ne s’agit pas ici de la négation descriptive , mais
d’une négation métalinguistique que les linguistes explique par le critère :
Tu n’as pas le droit de dire que…. Donc, le locuteur de la
huitième phrase voulait dire à son allocutaire : « Tu n’as pas le droit de dire que cet homme est seulement intelligent, mais tu dois dire plutôt,
il est un génie. »
La négation métalinguistique , on le voit, est une négation
rhétorique ; contrairement à la négation descriptive , très utilisée
en domaines scientifiques , qui veut dire « donc X est moins que P »
qui n’est applicable que pour des unités lexicales
pouvant former une échelle argumentative. Par exemple, la négation dans
« Il ne fait pas chaud » est descriptive , car on peut dire :
« Il ne fait pas chaud , donc il fait moins que chaud, par exemple , le
climat est froid ou le climat est tempéré »
Toutes ces choses importantes qu’on a vues jusqu’ici sont en guise
d’une introduction pour affleurer par suite une nouvelle approche de calcul de
la coordonnée sémantique , un calcul basé sur une perspective linguistique
contemporaine à la question de compréhension
textuelle . 2- Perspective linguistique contemporaine : une nouvelle approche de calcul de la coordonnée sémantique.
Je pense que la compréhension textuelle est fondamentalement attachée
au processus de dégagement de divers contenus sémantiques repérés dans le
texte projet de compréhension ou d’analyse. En outre, on se rappelle toujours
que les contenus sémantiques ne sont pas tous sur un même point de profondeur
et de degré. D’autre part, cette approche syntaxique devrait être précédée
par des activités lexicologiques structuralistes comme l’étude
componentielle des unités lexicales pertinentes (analyses sémiques), l’étude
des champs lexicaux , l’étude des sémiotiques jugées importantes…
Deux concepts linguistiques sont employés pour formuler cette approche : Le
premier, fondé par le philosophe Jean Langshaw Austin , est la notion de
l’acte illocutoire ou illocutionnaire qui, dans une autre terminologie, est
nommé acte performatif. Le
deuxième étant la notion de prédicat performatif
qui forme avec le sujet une phrase abstraite dont le référent
extralinguistique est l’acte illocutoire attaché au contenu sémantique. Le
prédicat performatif peut être explicite comme dans l’énoncé « Je
suis sûr et certain que celui qui fait du bien ne regrettera jamais »
. l’expression « être sûr et certain » représente le prédicat
performatif , le pronom personnel « je » est le sujet, et la phrase
« je suis sûr et certain » dénote l’acte illocutoire auquel sera
attribué au moins un contenu sémantique. C’est-à-dire, le nombre d’actes
illocutoires repérés dans un
texte est strictement inférieur (1[h1][h2])
au nombre de contenus sémantiques dégagés. Il peut être également implicite
comme dans l’énoncé « celui qui fait du bien ne regrettera jamais ». Les
contenus sémantiques dans un texte peuvent , par conséquent , être dégagés
en calculant les prédicats performatifs explicites ou implicites ; de la même
manière peut être déterminée la force illocutoire du texte . Ainsi, de l’énoncé
« Je suis sûr et certain que celui qui fait du bien ne regrettera
jamais », on dégage le premier contenu [C1=Celui qui fait du bien ne
regrettera jamais] ; mais le même énoncé renferme un prédicat
performatif implicite ou, selon la terminologie d’Austin, primaire qui
est le verbe « nier » et le deuxième contenu serait [C2= le
locuteur nie que celui qui fait du bien regrette son action].
Les prédicats performatifs sont donc des véritables indicateurs de
contenus sémantiques alors que la sémiotique des prédicats performatifs est ,
quant à elle, un indicateur de la force illocutoire du texte. Ils aident également
l’interprétateur à comprendre les intentions illocutoires du locuteur. Or si
on parvient à comprendre les objectifs et les intentions du locuteur, on sera
plus proche de comprendre son énoncé.
On procède maintenant à illustrer cette première phase de notre
approche à travers une série d’énoncés exprimés en français ou en arabe :
Mais avant d’entamer cette tâche qui consisterait à traiter les énoncés ci-dessus selon le concept de prédicats performatifs , on se sent obliger d’émettre quelques remarques préventives : Ø
Les contenus
qu’on va extraire du texte diffèrent de point de vue pertinence et fond sémantique ; Ø
L’acte
illocutionnaire présupposé acquiert une importance particulière , étant donné
qu’il est sujet d’unanimité entre le locuteur et l’allocutaire et
d’autres , et qu’il est généralement l’un des moyens les plus utilisés
en argumentation , et par voie de conséquence , il occupe un site privilégié
dans la genèse des discours cohérents . Les linguistes ont mis en place de
nombreux tests pour mettre en évidence le présupposé dans un texte. Ce sont généralement
des tests grammaticaux dont le plus connu est le suivant : le présupposé
reste indifférent de point de vue informatif lorsque le texte original est nié
. Ainsi, l’énoncé (1)« L’appareil électrique ne fonctionne plus »
pose que(2) « L’appareil électrique ne fonctionne pas au moment d’énonciation
t0 » et présuppose que (3)« L’appareil fonctionnait avant le
moment d’énonciation t0 » . La négation de l’énoncé original
donne(1)’ « L’appareil électrique fonctionne » et l’on
remarque par là que l’énoncé (3) conserve toujours sa véracité
linguistique et sémantique. Ø
L’interprétateur
et le locuteur ne réfèrent pas nécessairement à la même personne : le
locuteur peut être unique ou pluriel , de même pour l’interprétateur ;
quant à l’auteur , c’est pour nous le propriétaire effectif du texte ,
c’est-à-dire, ce locuteur qui a utilisé ses compétences linguistiques,
encyclopédiques, culturelles et sociales pour faire la performance de
production textuelle . L’interprétateur ,ou le lecteur, est pour nous ce récepteur
actif qui entreprend comprendre le texte en dégageant certains de ses contenus
pertinents. Ø
Les textes qui
seront objet de notre analyse ne sont que des occurrences soumises à un
contexte donné, et auxquelles sont
rattachés les contenus dégagés. Ainsi, si le présent du verbe «أحسن »
de l’énoncé 4 est déictique , ce dernier pourrait avoir une valeur « d’insulte »,
mais s’il n’est pas déictique , l’énoncé pourrait avoir une valeur de
« sagesse » ou de « conseil »… Parmi
les contenus que nous pouvons dégagés des énoncés (1), (2), (3), (4), (5)
,(6), (7) ,(8) , (9) et (10), on cite : Énoncé
(1) :
Énoncé(2) :
Énoncé(3) :
Énoncé(4) :
Énoncé(5) :
Énoncé(6) :
Énoncé(7) :
Énoncé(8) :
Énoncé(9) :
Énoncé(10) :
4)
Ducrot et Anscombre :
Correspondance entre le contenu comme hypothèse interne et l’acte illocutoire
comme hypothèse externe L’approche
d’analyse textuelle adoptée ici est inspirée des linguistiques textuelles
actuellement en vigueur . Elle est caractérisée par sa transcendance pour
atteindre les segments textuels . Ducrot et Anscombre ont contribué à l’évolution
de cette perspective textuelle notamment dans leur ouvrage « L’argumentation
dans la langue » publié en 1988. On va maintenant produire fidèlement
ce que nous considérons comme un soutien de grande envergure et comme une base
théorique très solide en faveur de la présente phase d’approche d’analyse
textuelle. Il s’agit d’une mise à connexion solide entre l’acte
illocutoire et les contenus sémantiques qui lui sont affectés. « A
l’hypothèse externe d’acte de parole correspond l’hypothèse interne de
contenu(…) Le concept de « contenu » fait partie du corps des
hypothèses internes : on pourrait tout aussi bien opter pour un autre type
de représentation sans que l’objet linguistique à décrire en soit modifié.
Alors que nous affectons à l’énoncé « je viendrai demain » le
contenu[je viendrai demain]affecté du marqueur d’acte illocutoire « Assertion »
. La sémantique générative, partant du même donné, fait une hypothèse
interne différente, dite hypothèse performative : à l’énoncé
« je viendrai demain » correspond au niveau de la machine la structure « je dis que je viendrai demain ».
(J.C.Anscombre et O. Ducrot 1988 : 38 – 39)
Donc,
l’hypothèse interne du contenu correspond à l’hypothèse externe de
l’acte illocutoire. « Remarquons
également que les contenus sont des rouages de la machine , c’est-à-dire ,
des formules du métalangage : ce ne sont donc pas des énoncés , même
si, faute d’un métalangage constitué, nous nous voyons contraints de représenter
ces contenus sous forme d’énoncés (…)Pour réduire ce risque , nous ferons
les conventions graphiques suivantes : « je promets de bien
travailler » sera un énoncé-occurrence ; [je travaillerai bien] le
contenu correspondant . »(Ibidem :38). « Les
marqueurs d’actes illocutoires indiquent les potentialités illocutoires de
l’énoncé, et servent donc à prédire que l’on ne pourra procéder à l’énonciation
de l’énoncé considéré sans par là-même effectuer un certain nombre
d’actes de parole . C’est ainsi que « je promets de bien travailler »
se verra affecter d’un contenu de genre de[je travaillerai bien] accompagné
du marqueur d’acte illocutoire promesse » (Ibidem :38).
5)
Structure illocutionnaire et structure modale Nous sommes
maintenant très convaincus que les actes illocutoires
contribuent énormément à la compréhension textuelle . Effectivement,
nous avons vu que les actes illocutoires , de quelque nature qu’ils soient,
reflètent une structure syntagmatique appelée « phrase de prédication ».
En guise d’une nouvelle terminologie, on parlera d’ores et déjà de
structure illocutoire. Le concept de
structure modale maintient des relations bien fondées avec le champ
cognitif de sémiolinguistique, il a été illustré notamment par A.J.Greimas .
En formulation très simpliste , la structure modale est une phrase composé de
deux énoncés : l’énoncé modal et l’énoncé modalisé. Cette
structuration nous permet d’appréhender le contenu sémantique de l’énoncé
modalisé par l’énoncé modal. Ainsi la phrase « je peux atteindre le
sommet de la montagne » est une structure modale
dont l’énoncé modal est « je peux » et l’énoncé
modalisé est « atteindre le sommet de la montagne ». Cette définition
nous permet de déclarer que toute
structure illocutoire est une structure modale, de même , toute structure énonciative
est également une structure modale. La structure modale peut toujours être
projetée sur la carré sémiotique ; mais avant de procéder à des
projections , on doit d’emblée savoir ce que cette notion de carré sémiotique ? Dans le Dictionnaire raisonné de la théorie
du langage de A.J.Greimas et Courtés , à l’entrée
« carré sémiotique », on sélectionne la définition
suivante : « …Il est maintenant possible de donner une représentation
définitive de ce que nous appelons carré
sémiotique :
La
projection d’une structure modale sur le carré sémiotique à trois
structures modales en plus de la structure d’origine et chaque structure est
affectée d’une valeur modale . Pour illustrer la projection d’une structure
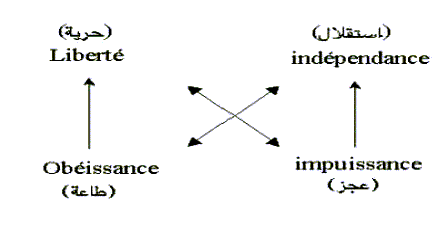
modale , prenons l’exemple de la structure pouvoir-faire,
proposé par Greimas :
On
peut ensuite transformer chaque pôle du carré sémiotique en valeur modale, et
on obtient le carré suivant dont les valeurs modales sont proposées toujours
par Greimas :
D’après
le structure du carré , la liberté et l’impuissance sont contradictoires et
de même pour l’obéissance et l’indépendance. Mais cela dépend du
contexte , car le vrai musulman par
exemple obéit à Dieu pour vivre indépendant . Donc, dans un tel contexte ,
l’obéissance et l’indépendance ne sont pas contradictoires, mais à vrai
dire , sont complémentaires. D’après
le carré , l’obéissance et la liberté sont complémentaires , pour cela ,
les deux implications suivantes devront être admises : Je
ne suis pas libre , implique que j’obéis . Je
suis libre, implique que je n’obéis pas.
Ici
encore c’est le contexte qui décide ; En effet , les croyants obéissent
à Dieu pour vivre en pleine liberté…
En conclusion, et de peur de s’égarer dans un domaine sémiolinguistrique
pas facile à franchir, les valeurs modales attribuées aux structures modales dépendent
toujours du contexte . Comment
les structures modales contribueront-elles à comprendre les textes et à les
analyser ? Avant
de répondre à cette question , deux grands défis attendent d’être levés : 1-
La plupart des structures modales sont non lexicalisées : les
expressions suivantes sont rarement en usage
« je ne dois pas ne pas… », « je ne pense pas ne
pas… », « il ne veut pas ne pas… »…Or, toutes les
structures modales font partie du
bon style. En outre, excepté les structures modales traitées par Greimas, la
majorité de ces fameuses structures est oubliée . De plus, les interprétateurs
n’accordent pas suffisamment d’importance
aux transformations des structures modales en valeurs modales. En réalité, la
sémiotique des structures modales est très étendue , elle englobe en effet ,
outre les structures modales ordinaires, les structures illocutoires ,les
structures énonciatives et les
structures modales énonciatives. 2-
On
rencontre de grandes difficultés lors
des opérations de transformations de structures modales en valeurs modales,
chose qui est due essentiellement à la subjectivité de ces valeurs et au fait
qu’elles soient soumises à des critères contextuels variables d’une société
à l’autre.
En résumé, l’approche de calcul des contenus sémantiques se trouve ,
à ce niveau complétée par un autre élément important : les structures
modales et leur transformation en valeurs modales.
5) Structure modale de
l’énonciation projection sur le carré sémiotique
Nombreux sont les linguistes, parmi lesquels on cite J.Dubois,
A.J.Greimas, C.K.Orrecchioni et d’autres,
qui définissent l’énonciation comme étant une phrase abstraite ,
implicite et antérieur à l’énoncé -occurrence sous la forme « Je
te dis que… » . De cette définition , on peut accéder à une
structure modale spécifique pour l’énonciation , dont l’énoncé modal
est l’énonciation et l’énoncé modalisé est l’énoncé
-occurrence. Cette
structure modale énonciative se projette ,elle aussi,
sur le carré sémiotique pour obtenir les deux catégories modales que
suivantes qui sont reproduites en arabe un peu plus bas :
Ces deux catégories sont soumises aux valeurs modales suivantes :
A partir de ce carré, car très génératif,
l’énoncé ,de quelque nature qu’il soit, est dupliqué en un grand
nombre d’énoncés générés( au moins quatre éventualités sont possibles).
Par exemple, l’énoncé « La température d’un solide augmente au
chauffage » est un dire-faire, c’est-à-dire une assertion positive
affirmé par le locuteur. Mais, il renferme aussi des « ne pas dire-faire »
comme l’énoncé « je ne dis pas que le température d’un
solide diminue au chauffage »(négation positive) , et
des « dire-ne pas faire » tel l’énoncé « je dis
que la température d’un solide ne diminue pas au chauffage »(assertion
négative), et des « ne pas dire-ne pas faire » comme c’est le cas
pour l’énoncé « je ne dis pas que la température d’un solide
n’augmente pas au chauffage »(négation négative). Donc,
si le locuteur dit un énoncé positif(affirmatif) , il dit en même temps des
énoncés négatifs et ne dit pas d’autres énoncés positifs et négatifs.
C’est à l’interprétateur qu’il revient de découvrir ces choses que le
locuteur , à dessein ou non, veut laisser à l’ombre.
Le modèle analytique exposé ici est réputé
la cheville ouvrière de notre approche de compréhension textuelle :
c’est en effet une application
directe de la notion du carré sémiotique comme conçue par A.J.Greimas et
J.Courtès dans : « Sémiotique :Dictionnaire raisonné de la théorie
du langage ».C’est aussi un modèle global dans cet ordre qu’il
englobe de nombreuses relations linguistiques comme la contrariété , la
synonymie, l’antonymie, l’hyponymie, l’hypéronymie, la complémentarité,
la contradiction, etc. En outre, il entreprend les unités lexicales en usage
dans des énoncés et non isolées. On
se rappelle en fin que les structures modales énonciatives ,dont les deux catégories
sémiotiques sont traduites ci-dessous en arabe, sont la base de ce modèle énonciative :
Afin de renforcer ce modèle très évolué , qu’on prétend avoir éveillé
( c’est-à-dire, il existait en puissance grâce aux spécialistes en domaine
de la sémiolinguistique), on ajoute quelques exemples à l’instar de
l’exemple précédent : (1)
:Le cuivre est un conducteur
(1)’:
je dis que le cuivre est conducteur (Assertion positive) (1)’’:
je dis que le cuivre n’est pas isolant (Négation positive) (1)(3):
Je ne dis pas que le cuivre soit isolant (Assertion négative) (1)
(4): Je ne dis pas que le cuivre ne soit pas conducteur (Négation
négative)
La
relation d’antonymie a été exploitée pour deux unités lexicales « conducteur »
et « isolant », chose qui a permis d’améliorer l’analyse des
propos du locuteur. La structure modale principale dans ce cas est un « dire-être »,
car informe sur l’état du cuivre.
(2):
Le crotale repère sa proie à sang chaud aussi bien de jour que de nuit '(2) :
Je dis que le crotale repère sa proie à sang chaud aussi bien de jour
que de nuit. '(2) :
Je dis que le crotale ne repère sa proie à sang froid que de jour. "(2) :Je
dis que le crotale ne repère pas sa proie à sang froid de nuit. (3)
(2) :
Je ne dis pas que le crotale repère sa proie à
sang froid aussi bien de jour que de nuit. (4)
(2) :Je
ne dis pas
que le crotale ne repère pas sa proie à sang froid de jour seulement.
Dans ce deuxième raisonnement, c’est la relation de complémentarité
entre les deux expressions : « proie à sang chaud » et
« proie à sang froid », qui
a été mise en valeur . D’ailleurs, les implications suivantes sont bien vérifiées :
X
est une proie à sang chaud
X
n’est une proie à sang chaud
A
ce niveau, je pense avoir donner brièvement un aperçu général d’un modèle d’analyse textuelle,
qu’on croit complet et global, jusqu’à preuve de contraire. Cette approche
est axée sur des concepts centraux tels que les actes illocutoires, le dégagement
des contenus sémantiques, les structures modales et leur relation aux
structures illocutoires, les structures modales énonciatives et l’interprétation
sémiotique des textes. Ce sont des concepts fortement liés et connectés nous
permettant de bien comprendre le
texte projet de traduction . 6)
Modalisation énonciative d’une structure modale
§ projection général
§
Projections
secondaires
Remarque :
En logique mathématique la proposition ~(P
Λ
q) est équivalente à la proposition( ~q
V ~P) ; mais, pour
nous , nous n’avons pas l’intention de se lancer dans des problématiques de
conjonction et disjonction , et nous allons nous contenter de remplacer la
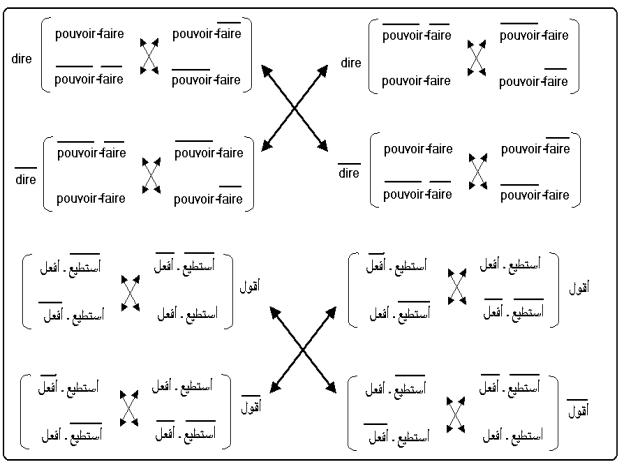
structure « ~(pouvoir-faire) » par « ~pouvoir-~faire ».
En procédant à des réductions et à des redistributions de « dire »
et « ~dire », on
obtient le modèle sémiotique suivant qui n’est plus un carré , mais un
hexagone ayant 8 pôles, donc 8 valeurs modales :
C’est
un modèle hétéroclite et bizarre que je ne sais quelle valeur aurait aux yeux
d’un sémioticien ?!
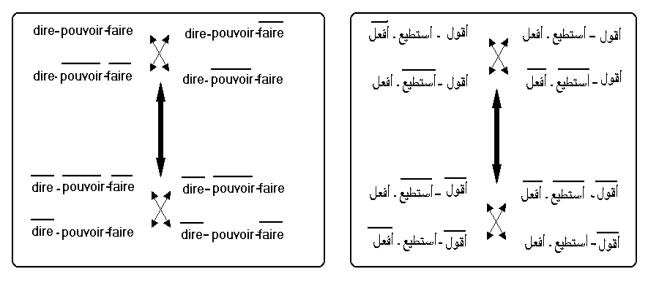
Dans notre contexte, un exemple suffirait pour un
peu illustrer cette
structure soit disant casse tête : Soit
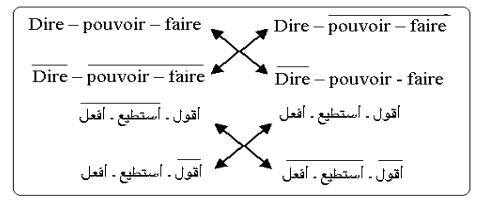
la structure suivante : « Je
dis que tu peux voyager » Les
catégories modales dérivées de cet énoncé principal sont : 1°/
Je dis que tu peux voyager
2°/ Je dis que tu peux ne pas voyager 3°/
Je dis que tu ne peux pas voyager 4°/
Je dis que tu ne peux pas ne pas voyager
5°/
Je ne dis pas que tu puisses voyager
6°/
Je ne dis pas que tu puisses ne pas voyager 7°/
Je ne dis pas que tu ne puisses pas voyager 8°/
Je ne dis pas que tu ne puisses pas ne pas
voyager Focalisation
J’avais
affirmé ultérieurement que les structures modales énonciatives constituent un
modèle très évolué d’analyse textuelle. En effet, ces structures sont
implicitement présentes dans tout
énoncé et leur projection sur le carré sémiotique conduit à la génération
d’un grand nombre , voire illimité, de phrases renfermant divers contenus sémantiques,
le minimum étant quatre structures :assertion positive, assertion négative,
négation positive et négation négative. S’additionnent à ce composé
analytique les contenus d’origine les structures modales non énonciatives
foisonnantes en tout genre textuel …A ne pas oublier les contenus issus de
structures illocutoires proprement dites. Dans cette perspective, un seul énoncé
d’un texte pourrait être à l’issue d’une véritable texture de contenus
sémantiques. Toutefois,
à la traduction c’est l’énoncé d’origine qu’il fallait
traduire
et non point les contenus sémantiques dégagés . C’est, en effet,
au niveau de cet énoncé que se réalise, à part entière, les
composantes du sens. Ainsi , l’énoncé occurrence « le cuivre est un
conducteur » et la phrase analytique « le cuivre n’est pas un
isolant » ne sont pas équivalents à cent pour cent, car leurs sens
contextuels sont différents ,dès lors que l’énoncé est tributaire de
circonstances communicationnelles autres que les circonstances
dont dépend la phrase abstraite. Maintenant
qu’une machine analytique évoluée est à la disposition du traducteur qui
peut procéder à son usage pour analyser les textes , ce dernier ne doit pas
oublier que le repérage et la comparaison des sémiotiques au sein du texte est
un autre aspect métatraductologique de
plus haute importance . C’est justement l’objet de la partie qui va suivre.
II- Equations paradigmatiques)
Say1<=>
Say 2(
D’une
manière générale, il s’agit ici d’un travail de repérage et de sélection
de sémiotiques pertinentes dans le texte source, de comparaison des
fonctionnements de chacune des sémiotiques repérées dans le texte cible et
d’établissement d’équations paradigmatiques. La comparaison des sémiotiques
fait appel aux savoirs métatraductologiques accumulés par le traducteur le
long de son expérience en traduction .
Pour les élèves lycéens en classes scientifiques et techniques , là où
c’est question de textes à contenus scientifiques, une sémiotique se présente
toujours en avant-garde : la sémiotique des termes scientifiques.
Cette sémiotique est généralement traitée à travers un ensemble
d’activités : Ø
Les
termes scientifiques sont repérés , sélectionnés puis classifiés. On adopte
à ce niveau la classification citée dans (N.
HALI, 2000. p: 45) :
les termes scientifiques peuvent être classifiés en deux catégories :
des termes comme images mentales qui sont des termes formulés pour dénoter
des phénomènes naturels conçus par l’homme lui-même, ces termes réfèrent
souvent à des objets abstraits et non concrets (photosynthèse, hydrolyse, hémolyse,
reproduction…) et des termes comme mots techniques formulés pour rendre des
constituants des objets que le chercheur utilisent lors de son activité
scientifique ; ils peuvent être des éléments de la nature (mercure,
atome, hydrogène, roche, gaz…) ou des moyens utilisés par le chercheur en sa
recherche scientifique (microscope, générateur, ordinateur, lentille, …). Ø
Étude
de la dérivation propre des termes qui s’effectue , selon Ahmed Al Akhdar
Ghazal, par des préfixes et des suffixes rattachés aux infixes. C’est donc là
une activité proprement morphologique. D’autre
part, l’établissement de l’équation paradigmatique à base de la sémiotique
des termes scientifiques s’effectue en trois phases reproduites ici, car déjà
vues au chapitre 3 de cette partie : a)repérage
des sémiotiques : L’équation
paradigmatique nécessite toujours, en première étape, que soit repérée la sémiotique
à la base de laquelle sera établie cette équation : la première phase
serait donc un repérage de la sémiotique en question . La sémiotique étant,
il ne faut pas l’oublier, un système de signes linguistiques dont les éléments
sont unis par au moins un rapport linguistique particulier. Ainsi , on peut,
dans un texte scientifique, repérer la sémiotique des termes scientifiques
appartenant au domaine scientifique du texte , et le critère de sémioticité
dans ce cas serait « termes scientifiques appartenant à un domaine
scientifique précis » b)équations
lexicales : A
ce niveau purement lexical, chaque élément de la sémiotique collectée est
traité indépendamment des autres : on lui attribue sa coordonnée
lexicale dans la langue de départ . Cette coordonnée constituerait le premier
pôle de l’équation lexicale . Ici également deux options sont possibles :
une équation lexicale primaire ,si le mot(ou l’expression) conserve les mêmes
sèmes grammaticaux lors du passage dans la langue cible ; une équation
secondaire si ces sèmes varient . Ces variations de sèmes grammaticaux entre
les langues sont due aux variations d’usage au sein des deux systèmes
langagiers . Si l’on considère par exemple l’expression « la petite
cuisine » , sa coordonnée
lexicale dans
la langue de départ est : Adj.+n.f et l’équation lexicale primaire
serait : Adj.+n.fÛصف.+
اس.مؤ.
. Mais cette équation n’est pas permise dans le système langagier arabe ,
car d’une part, l’adjectif en arabe ne peut pas précéder le qualifié
(‘almawŠūf) ; d’ou la première transformation ordinale .
D’autre part, le mot cuisine qui est de genre féminin en langue française ne
peut pas conserver le même genre si on considère le mot « maţbakh »
en langue arabe , par là est imposée la deuxième transformation . Donc, on
adopte l’équation lexicale secondaire suivante :
En résumé, l’équation paradigmatique d’un texte à base d’une sémiotique
donnée est constituée par l’ensemble des mots ou /et expressions et leurs équivalents
en langue cible, occupé au centre par des équations lexicales primaires ou
secondaires.
c)Établissement de l’équation paradigmatique.
N.B :
Nombreuses sont les sémiotiques qui coexistent au sein du texte, mais
dans notre cas, on a pris l’exemple de sémiotique des termes scientifiques
pour des motifs purement pédagogiques et didactiques qui concerne justement
notre domaine d’action pédagogique. III-
Phase de traduction : La
phase de traduction nécessite que soient effectuées les activités suivantes : 1-
Découpage du texte en unités syntagmatiques appelées unités de
traduction (Ut). Parmi les critères adoptés pour faire ce découpage la non
appartenance du connecteur logique à l’unité de traduction,
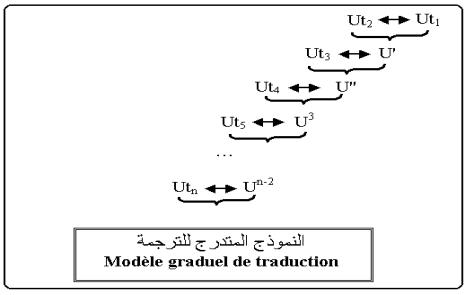
l’accomplissement de l’unité syntagmatique. .. 2-
Traduction du texte par usage du modèle graduel de traduction schématisé
ci-dessous : c’est un modèle qui vise la traduction du texte unité par
unité. Ainsi, on traduit les
deux unités Ut1 et
Ut2
, puis on les connecte par le lien logique convenable pour obtenir une unité
plus grande(U’) , et ainsi de suite jusqu’à l’obtention d’un texte cohérent.
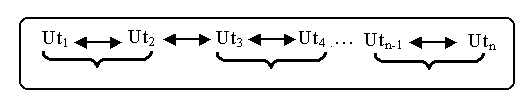
Il
existe un autre modèle de traduction nommé modèle linéaire, mais il
difficile à appliquer surtout s’il s’agit de traduction d’un texte relativement long :
Quant à
la traduction d’une unité, elle se fait selon l’unité syntagmatique
primaire (Sax1⇔Sax2)
,si le produit obtenu est conforme au génie de la langue cible, et exempt
d’erreurs sémantiques ,stylistiques ou rhétoriques ; sinon le recours
à la traduction libre sera obligatoire , dans ce cas ,c’est une équation
syntagmatique secondaire qui sera appliquée.
Le modèle graduel de traduction acquiert une importance particulière au
niveau pédagogique . L’enseignant peut , en effet, l’appliquer
au cours de l’opération d’enseignement et d’apprentissage. Par
ailleurs, c’est un moyen pédagogique très efficace , au cours duquel
l’apprenant acquiert des techniques de formulation des textes soumis aux
principes de cohérence et cohésion textuelles : il apprend comment
manipuler les connecteurs logiques et les anaphoriques et appréhende leurs mécanismes
de fonctionnement et dans le texte source et dans le texte cible. Bref , c’est
un modèle pratique et réaliste applicable au niveau du groupe classe.
IV-
Traduction par repérage et grammaire générative :
1)Grammaire
générative
« La grammaire générative est une théorie
linguistique élaborée par N.Chomsky dès 1960. Ce dernier définit une théorie
capable de rendre compte de la créativité du sujet parlant, de sa capacité à
émettre et comprendre des phrases inédites(…) Dans cette perspective, la
grammaire est un mécanisme fini qui permet de générer l’ensemble infini de
phrases grammaticales d’une langue . Cette grammaire , formée de règles définissant
les suites de mots ou de sons qui sont permises, constitue le savoir
linguistique des sujets parlant une langue, c’est-à-dire leur compétence
linguistique.
La
grammaire est formée de trois composantes : -
une composante syntaxique , système de règles définissant les phrases
permises dans une langue ; -
une composante sémantique, système de règles définissant l’interprétation
des phrases générées par la composante syntaxique ; -
une composante phonologique et phonétique , système de règles réalisant
en une séquence de sons les phrases générées par la composante syntaxique. La
composante syntaxique , ou syntaxe, est formée de deux grandes parties :
La base, qui définit les structures fondamentales ,et les
transformations , qui permettent de passer des structures profondes , générées
par la base , aux structures de surface des phrases, qui reçoivent alors une
interprétation phonétique pour devenir les phrases effectivement réalisées .
Ainsi, la base permet de générer les deux suites : (1)
La+mère+entend+quelque chose, (2)
L’+enfant+chante. La
partie transformationnelle de la grammaire permet d’obtenir La mère entend
que l’enfant chante et la mère entend l’enfant chanter . La
base est formée de deux parties : a-
base catégorielle, ensemble de règles définissant les relations
grammaticales (sujet-prédicat…)entre les éléments qui constituent les
structures profondes et qui sont représentés par des symboles catégoriels
(SN, SV,…) b-
Lexique, ou dictionnaire de la langue, ensemble des morphèmes lexicaux définis
par des séries de traits les caractérisant ; ainsi, le morphème « mère »
sera défini dans le lexique comme un nom, féminin, animé, humain…Si la base
définit la suite de symboles : Art+N+Près+V+Art+N, le lexique substitue
à chacun de ces symboles un « mot » de la langue : La + mère+t+finir+le+ouvrage,
et les règles phonétiques réalisent : La mère finit l’ouvrage. »
(Cf.:
Jean Dubois et al. 1973 : 226 – 227 ) 2)Mise
en évidence de la relation :
Le texte , selon le principe de repérage, possède trois coordonnées :
Sax , Say et Se’. Nous savons également que la base , selon la grammaire générative,
est constituée de deux dimensions :
dimension catégorielle, qui correspond relativement à la coordonnée
syntagmatique, et dimension
lexicale qui ressemble un peu à la coordonnée paradigmatique. Mais ,
les constituants de la base sont centrés sur les catégories grammaticales,
alors que la coordonnée syntagmatique est centrée sur les fonctions
grammaticales et la coordonnée paradigmatique sur les morphèmes.
Le plus utile de point de vue sémantique est de surpasser le niveau des catégories grammaticales à un
niveau , on le voit, plus évolué : celui des fonctions grammaticales de
ces catégories elles-même . Cependant, en tout état de cause, on peut dépasser
cet obstacle et essayer quand même d’attribuer
une interprétation générative pour la traduction à base du repérage
linguistique.
Que l’on considère le texte : (T1)L’aimant attire l’acier. Les coordonnées
de (T1) sont : Sax1=
S+Vt+COD Say1=
aimant + attirer+ fer On
peut écrire: B1=Sax1+
Say1
,
où B1 est la base dans (LD) En
outre, on sait que la base est une structure profonde qui génère un ensemble
infini de phrases . On dit, mais une autre transgression du code génératif,
qu’elle génère un ensemble infini de textes. On admettra , d’autre part,
que (T1) est un fils de B1ayantr une infinité de frères et sœurs . De là ,
on définit la détermination de la coordonnée syntagmatique du texte (T1)
comme étant un transfert d’une structure de surface (texte fils) vers une
structure profonde(base), c’est-à-dire, un retour à l’origine . Sauf dans
ce cas, on a pas le droit d’utiliser la composante transformationnelle de la
base , car il n’est pas permis au traducteur de modifier le texte source.
Après vient le tour des équations syntagmatiques et paradigmatiques, ou
ce qu’on peut appeler la transformation de la base B1 en B2 dans (LA) :
Pour
(T1) :
Sujet
+ Verbe + COD
aimant
+ attirer + fer
La
transformation qui s’est produite dans ce cas se rapporte à la position du
verbe qui revient , en arabe , en tête de la phrase.
La troisième phase est la passage de la base B2 vers la structure de
surface générée ( Produit de traduction (T2)).
[h1](1) A ce niveau là , je disait dans la version arabe de mes fondements théoriques (cf. Noureddine HALI 2003 p : 74 ) que le nombre d’actes illocutoires était égal au nombre de contenus sémantiques dégagés . C’est un résultat remis en cause ici , car les contenus sémantiques sont en réalité inépuisables
|
|
Envoyez un courrier électronique à halitraduire@yahoo.frpour toute question ou remarque concernant ce site
Web.
|